Peerless Info About Are There 3 Types Of Data

Data Types And Their Importance In Analytics Just Understanding
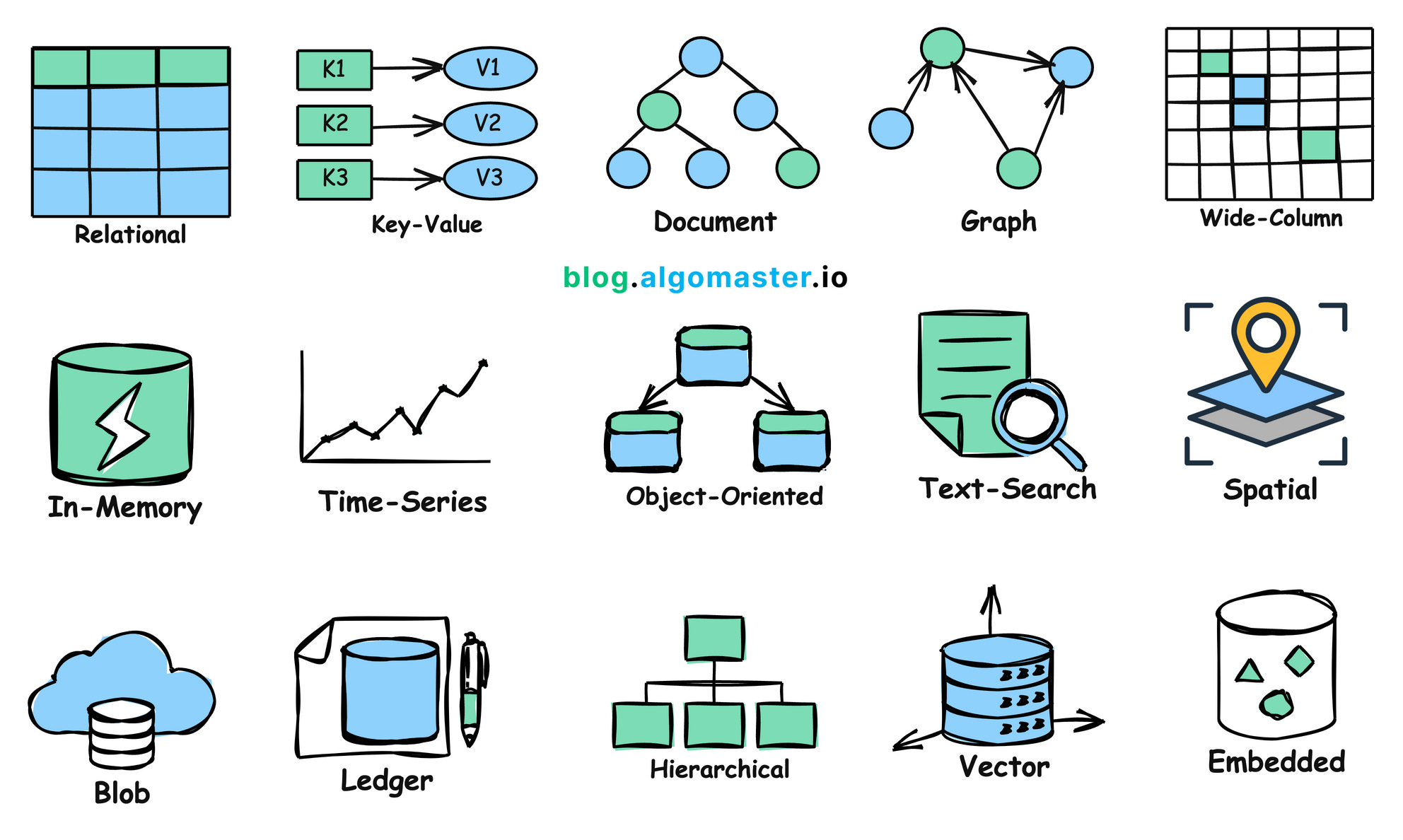
15 Types Of Databases And When To Use Them
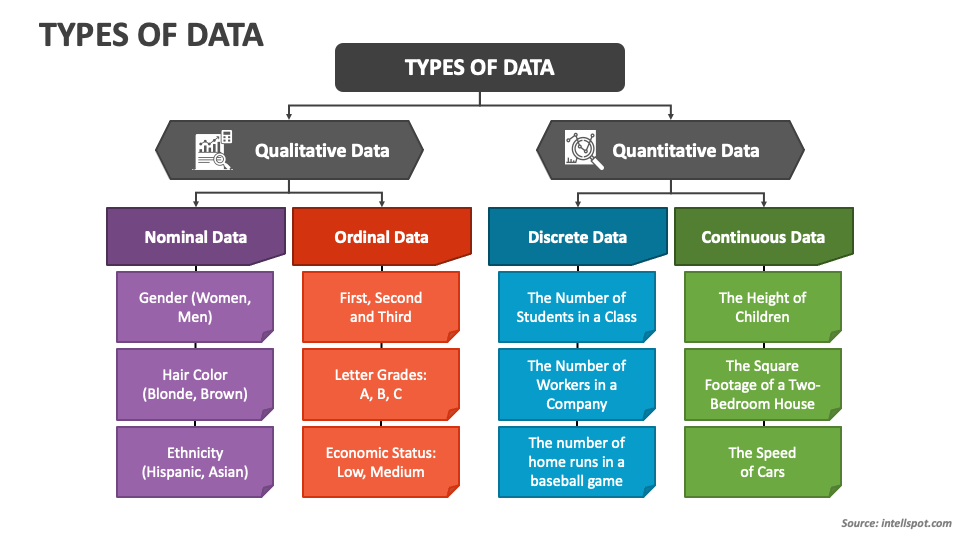
Types Of Data Powerpoint Presentation Slides Ppt Template

6 Types Of Data In Statistics & Research Key Science

3 Steps To Classify Your Financial Data
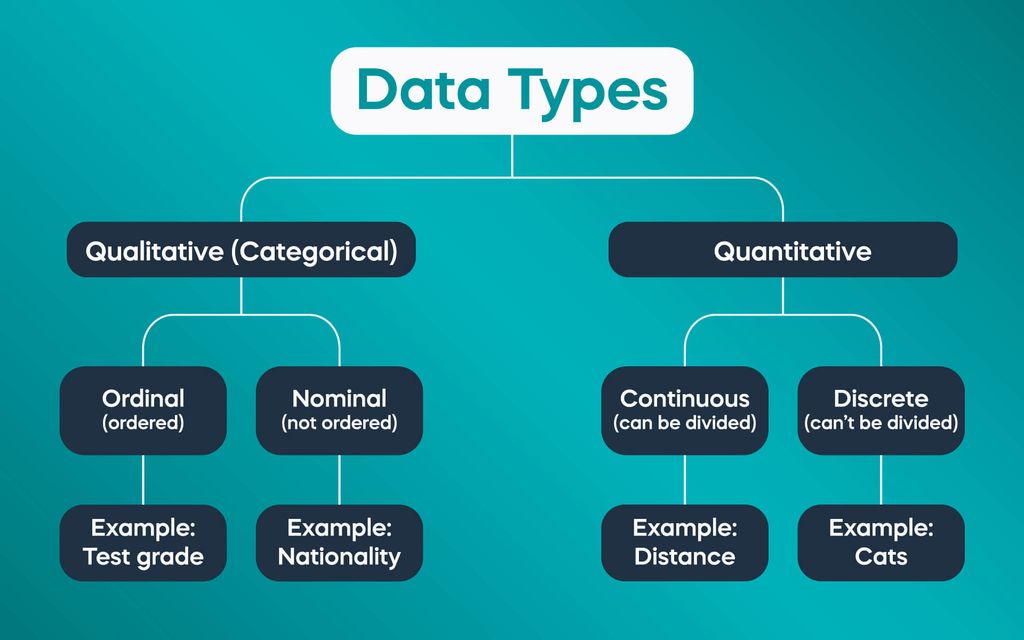
Data Types The Complete Guide For Beginners (2022) 365 Science

Peering into the Data Realm: Deconstructing the Notion of Three Data Forms
Does the Conventional Three-Part Division Still Hold Up?
For quite some time, the standard explanation in the world of data has often centered on what seemed like a straightforward division: structured, unstructured, and semi-structured data. This neat trio has served as a fundamental idea for many entering the field, offering a basic way to understand the different shapes information can take. You've likely encountered this classification in introductory lessons or casual chats about databases and data analysis. It's tidy, it's brief, and it's relatively simple to grasp. However, in today's rapidly changing digital world, where data creation is exploding in complexity and sheer volume, one might reasonably wonder: does this three-pronged view still accurately depict the subtle reality of the data we work with?
The appeal of this three-form model lies in its simplicity. Structured data, with its well-defined frameworks and relational databases, provides a sense of order and ease of querying. Picture spreadsheets or customer records — everything neatly arranged into rows and columns. Unstructured data, on the other hand, represents the more untamed side of information: text documents, images, videos, audio recordings, social media updates — a large and often less organized collection lacking a predefined framework. Semi-structured data attempts to bridge this divide, possessing some organizational qualities that make it easier to analyze than purely unstructured data, examples including JSON and XML files. This categorization has been helpful for initial understanding, but the distinctions are becoming increasingly less clear.
Consider the data produced by modern applications and sensors. Is a JSON document with nested arrays truly just "semi-structured"? Or does its inherent intricacy suggest a more detailed classification? Similarly, advancements in how computers understand language and images are allowing us to extract structured information from previously unstructured text and pictures, effectively blurring the boundaries of the traditional categories. The tools and methods we use to process and analyze data are also becoming more advanced, capable of handling a wider range of data formats with greater flexibility. This leads to the question: are we limiting our comprehension by adhering too strictly to this three-form idea?
Perhaps it's time to look beyond this simple classification and adopt a more adaptable and context-dependent way to understand data. Instead of focusing solely on inherent structure, we might consider characteristics like data origin, intended purpose, processing needs, and the degree of transformation applied. This shift in perspective could lead to more effective data management strategies and unlock new possibilities for analysis and gaining insights. So, while the "three forms of data" provides a useful starting point, a deeper look reveals a far more intricate and dynamic data landscape.
Venturing Beyond the Threesome: Investigating the Expanding Data Universe
Could There Be More Than Just Three Categories?
If we dare to venture beyond the comfortable limits of the traditional three data forms, what other viewpoints emerge? The truth is that data exists on a spectrum, and attempts to force every piece of data into one of three rigid boxes can be overly simplistic and potentially misleading. Think about the rich variety of data generated by the Internet of Things (IoT) devices. Sensor readings, while often numerical, can arrive in various formats and at different rates, sometimes showing characteristics of both structured and unstructured data streams. Classifying this diverse influx neatly into just three categories can hide important details and challenges in its management and analysis.
Furthermore, the concept of "data in motion" or streaming data presents a unique challenge to the traditional static view. This continuous flow of information, generated by sources like social media feeds, financial transactions, or industrial machinery, doesn't neatly fit into any of the three predefined buckets. Its time-sensitive nature and the need for real-time processing introduce a dimension that the static structured, unstructured, and semi-structured model doesn't fully address. How do we categorize a continuous stream of sensor readings that may contain both structured numerical values and unstructured textual notes?
The rise of graph databases also challenges the traditional relational focus of structured data. While graph databases possess a defined structure — nodes and connections — their emphasis on relationships and interconnectedness offers a fundamentally different way of organizing and querying information compared to tables and rows. Are these simply a type of structured data, or do their unique characteristics warrant a separate consideration? The ability of graph databases to model complex relationships opens up new avenues for analysis in areas like social networks, knowledge organization, and recommendation systems, highlighting the limitations of a purely relational view of structured data.
Moreover, the increasing prevalence of multimedia data, often containing a mix of formats, further complicates the traditional categorization. A video, for instance, contains visual information (unstructured), accompanying audio (unstructured), and potentially metadata like timestamps and location (structured or semi-structured). Attempting to classify the entire video as simply "unstructured" ignores the valuable structured and semi-structured elements it contains. This interconnectedness and the increasing sophistication of data formats necessitate a more flexible and multi-dimensional understanding of the data landscape.
The Blending Boundaries: When Categories Intermingle
The Interaction and Development of Data Forms
One of the most persuasive arguments for moving beyond the strict three-form classification is the increasing tendency for data forms to blend and develop. What starts as unstructured data can be processed and transformed into structured data, and the other way around. Natural language processing techniques, for example, can extract structured entities and relationships from unstructured text documents, effectively bridging the gap between these seemingly distinct categories. Similarly, structured data can be transformed into unstructured formats for visualization or storytelling purposes. This dynamic interaction highlights the limitations of a static, mutually exclusive categorization.
Consider the journey of a customer interaction. It might begin as an unstructured phone conversation, then be transcribed into text (still largely unstructured), analyzed using sentiment analysis tools to extract structured sentiment scores, and finally stored in a CRM database (structured). At each stage, the data undergoes a transformation, moving across the traditional boundaries. To rigidly classify the initial phone call and the final database entry as entirely separate "forms" overlooks the continuous development and interconnectedness of this information. The value lies not just in the initial shape but in the transformations and insights derived throughout its lifecycle.
The emergence of new data formats and technologies further blurs these lines. Consider data lakes, designed to store vast amounts of data in its original format, regardless of structure. This approach acknowledges the fluidity of data and the potential for future analysis that might require different structural interpretations. The ability to ingest and process diverse data types in a single repository challenges the need for strict upfront categorization. Instead, the focus shifts to tools and techniques that can dynamically adapt to different data formats and extract value regardless of its initial structure.
Ultimately, the rigid boundaries between structured, unstructured, and semi-structured data are becoming increasingly less distinct. The focus should shift from strict categorization to understanding the characteristics of the data, the tools available for its processing and analysis, and the specific insights we aim to extract. Recognizing this fluidity allows for more adaptable and effective data management and analysis strategies in the face of an ever-evolving data landscape. It's less about fitting data into predefined boxes and more about understanding its inherent properties and potential.
Optimizing for Discovery: Thinking Beyond Form
How to Make Your Content Stand Out in the Data Overload
Now, you might be wondering, how does all this discussion about data forms relate to optimizing for Google Discover and search rankings? Well, understanding the subtle aspects of data and how information is organized and presented is crucial for creating content that connects with both users and search engines. While Google doesn't explicitly rank content based on the "form" of data it discusses, the way you structure and present your information significantly impacts its discoverability and authority. Clear, well-organized content, regardless of the data it references, is more likely to be understood and valued by both algorithms and human readers.
Think about how you present complex information. Breaking down intricate concepts into manageable parts, using clear headings and subheadings (like we're doing here!), and providing context are essential for readability. This not only improves the user experience but also helps search engines understand the key topics and subtopics of your content. When discussing data, providing concrete examples and illustrating your points with real-world scenarios can make your content more engaging and easier to grasp. Remember, clarity and relevance are paramount in the eyes of Google's algorithms.
Furthermore, consider the format of your content. While this article is text-based, incorporating diverse media like images, videos, and infographics can enhance engagement and provide alternative ways for users to understand the information you're presenting. For example, if you're discussing statistical data, visualizing it through charts and graphs can be far more impactful than simply presenting raw numbers. Optimizing these visual elements with relevant alt text and descriptions also improves their discoverability in image and video search results, expanding your content's reach.
Ultimately, optimizing for discovery isn't about rigidly categorizing the data you discuss but about presenting it in a clear, engaging, and well-structured manner. Focus on providing valuable insights, supporting your claims with credible sources (if applicable), and ensuring your content is easily accessible and understandable across various devices. By prioritizing user experience and clarity, you're not just optimizing for search engines; you're creating content that truly connects with your audience, which, in turn, can lead to improved visibility and engagement on platforms like Google Discover.
Frequently Asked Questions: Deciphering the Data Discussion
Your Pressing Data Questions Answered (Hopefully with a Touch of Lightheartedness)
Alright, so we've journeyed through the fascinating, and perhaps slightly intricate, world of data categorization. You might have a few lingering questions swirling in your mind, like that one puzzle piece that always seems to go missing. Let's address some of those now, shall we?
Q: So, if there aren't *really* just three forms, why do so many people still talk about them?
A: That's a valid point! The "big three" (structured, unstructured, semi-structured) serve as a useful starting point, a kind of "Introduction to Data" if you will. It provides a basic framework for understanding the fundamental differences in how data is organized. Think of it like learning the primary colors before exploring the complexities of the color spectrum. It's a simplification, but a helpful one for those new to the subject. Plus, established ideas can persist, especially in the sometimes-conservative world of data management. It's familiar, like a well-loved book, even if it doesn't capture the entire story.
Q: If the distinctions are so subtle, how should I actually *think* about data?
A: Instead of focusing solely on rigid categories, try thinking about data in terms of its characteristics and how you intend to utilize it. Consider its origin, its format, the level of processing required, and the insights you hope to gain. Is it primarily numerical and easily organized? Is it free-form text requiring analysis? Does it have some inherent structure but also contains variable elements? This more nuanced approach allows for a more adaptable and effective strategy for managing and leveraging your data. It's like moving from "is it sweet or savory?" to understanding the individual ingredients and culinary potential of different foods.
Q: Does Google care if I talk about "three forms of data" in my content?
A: Google's algorithms are sophisticated enough to understand that this is a common introductory concept. However, if you're aiming for in-depth accuracy and demonstrating a strong understanding of the data landscape, it's beneficial to acknowledge the evolving nature of data and perhaps explore more nuanced classifications or the blurring of these traditional lines. Think of it as showing Google (and your readers) that you're not just repeating basic information but have a deeper comprehension of the subject matter. Plus, exploring these complexities can make your content more engaging and informative!
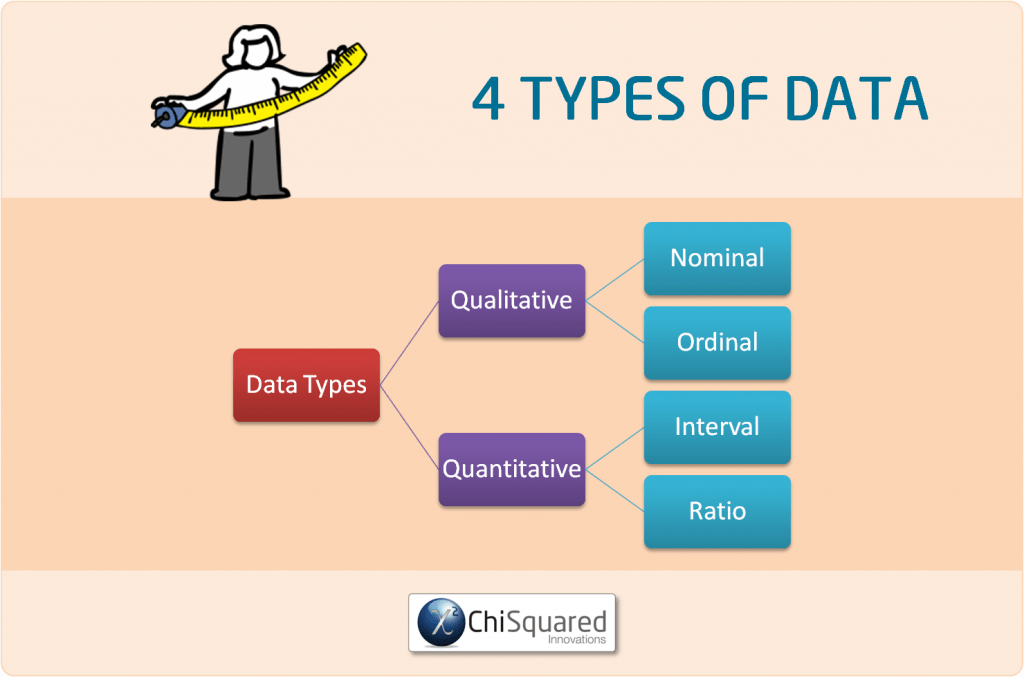
4 Types Of Data In Statistics Definitions, Uses & Examples
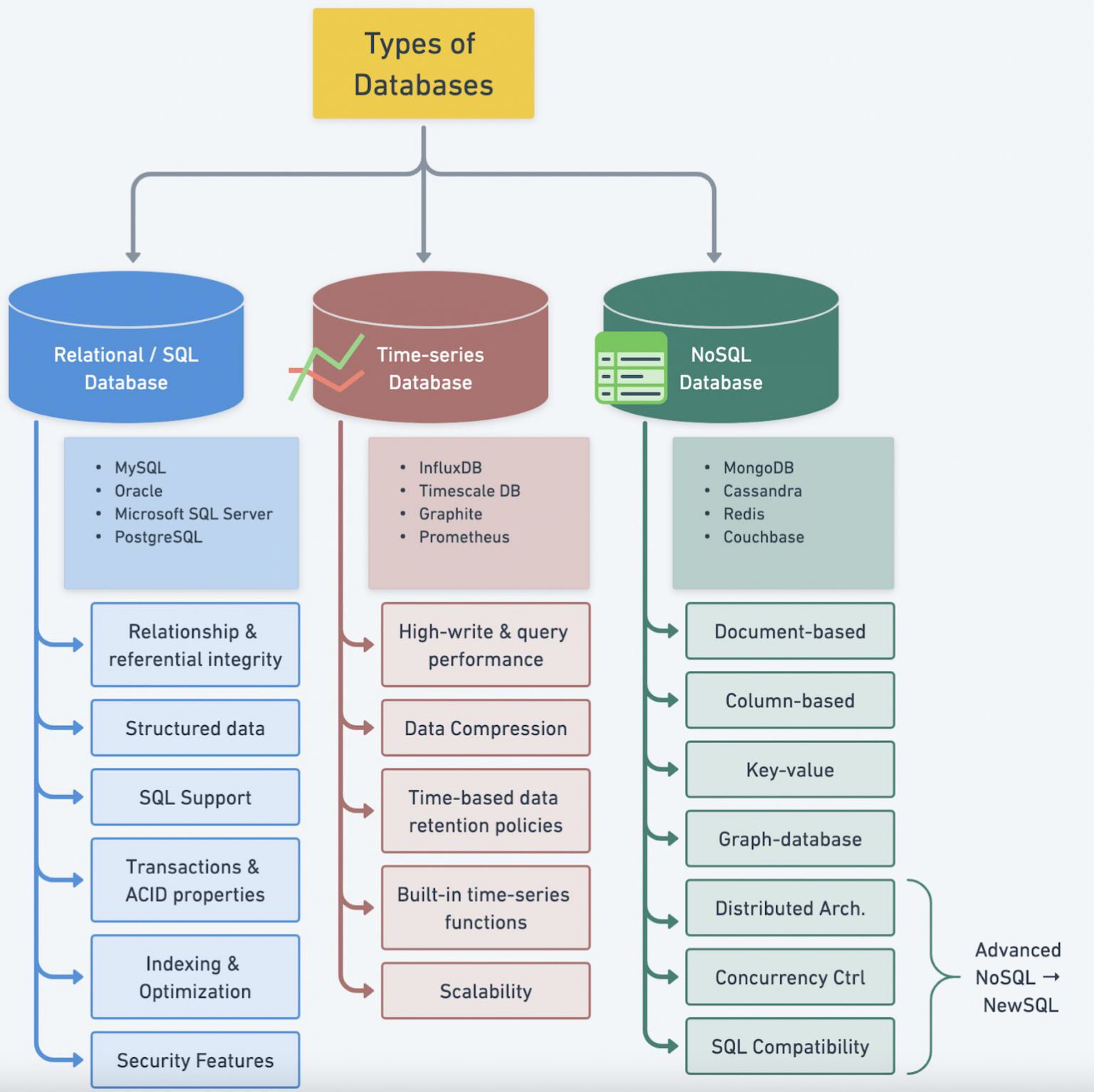
Types Of Databases
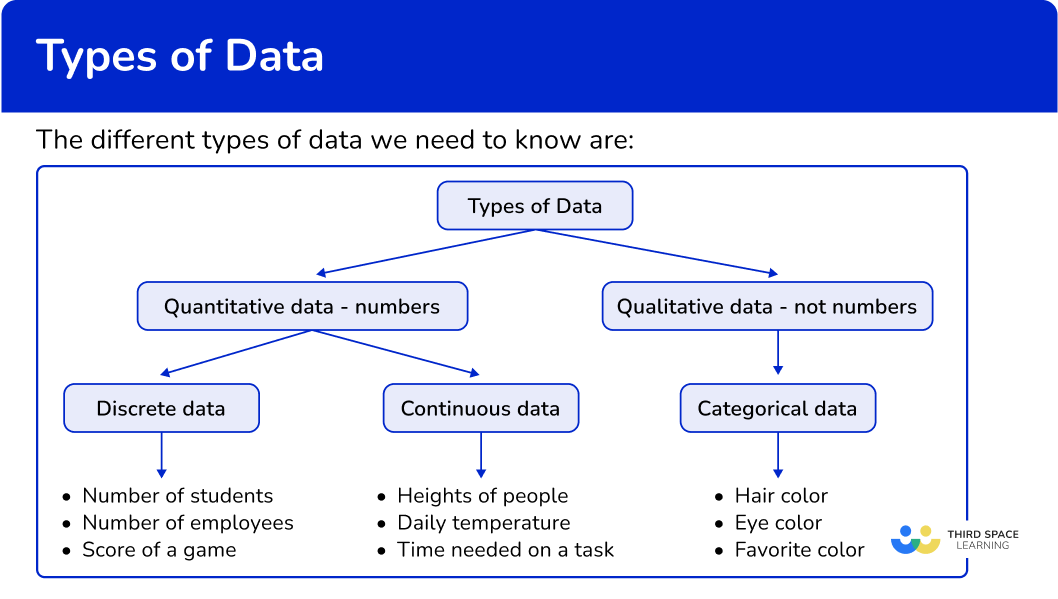
Types Of Data Math Steps, Examples & Questions
Types Of Data Gcse Maths Steps, Examples & Worksheet
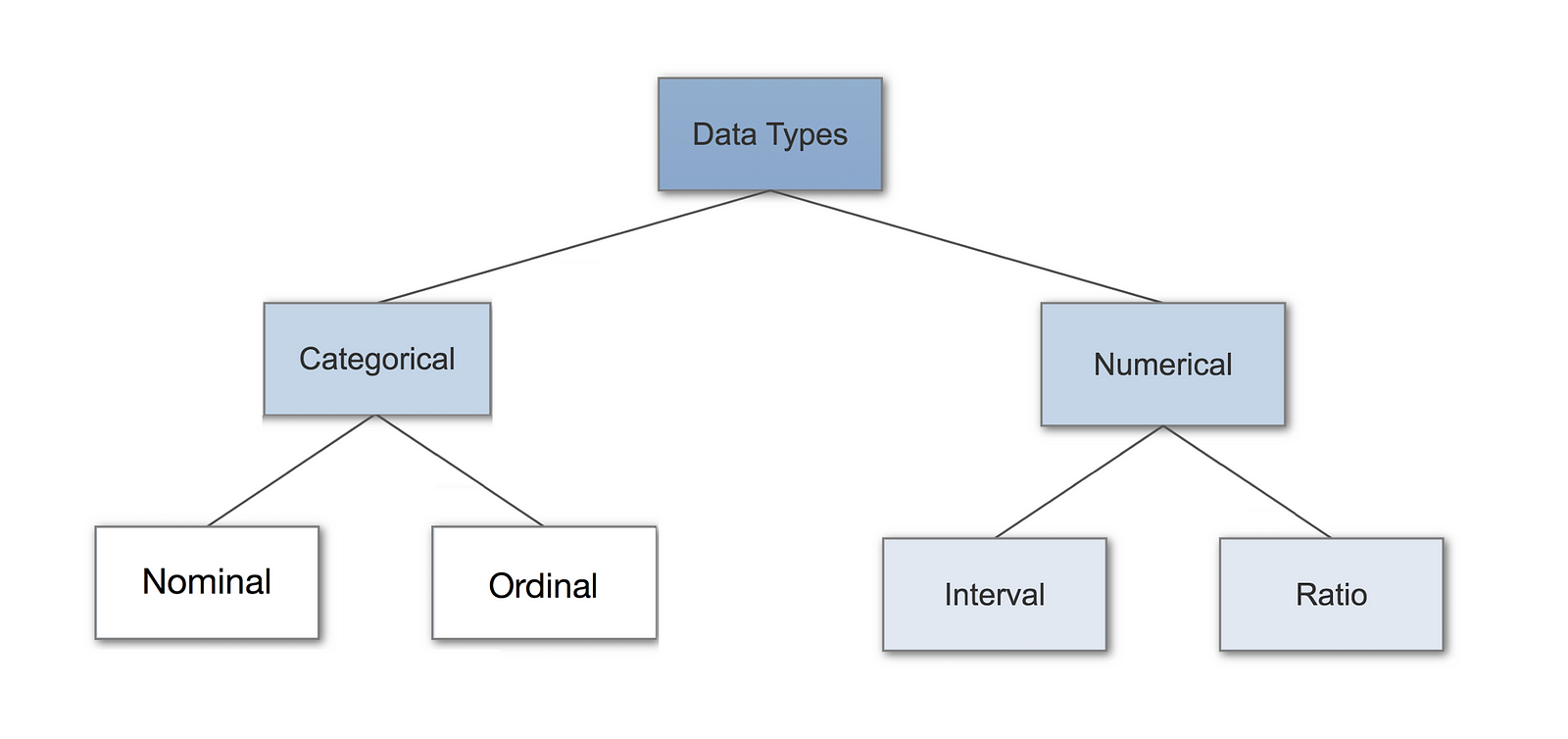
Maths 101 Part 1 Data Types And Their Visualization Coding Brewery

What Is Data Classification Best Practices And Types
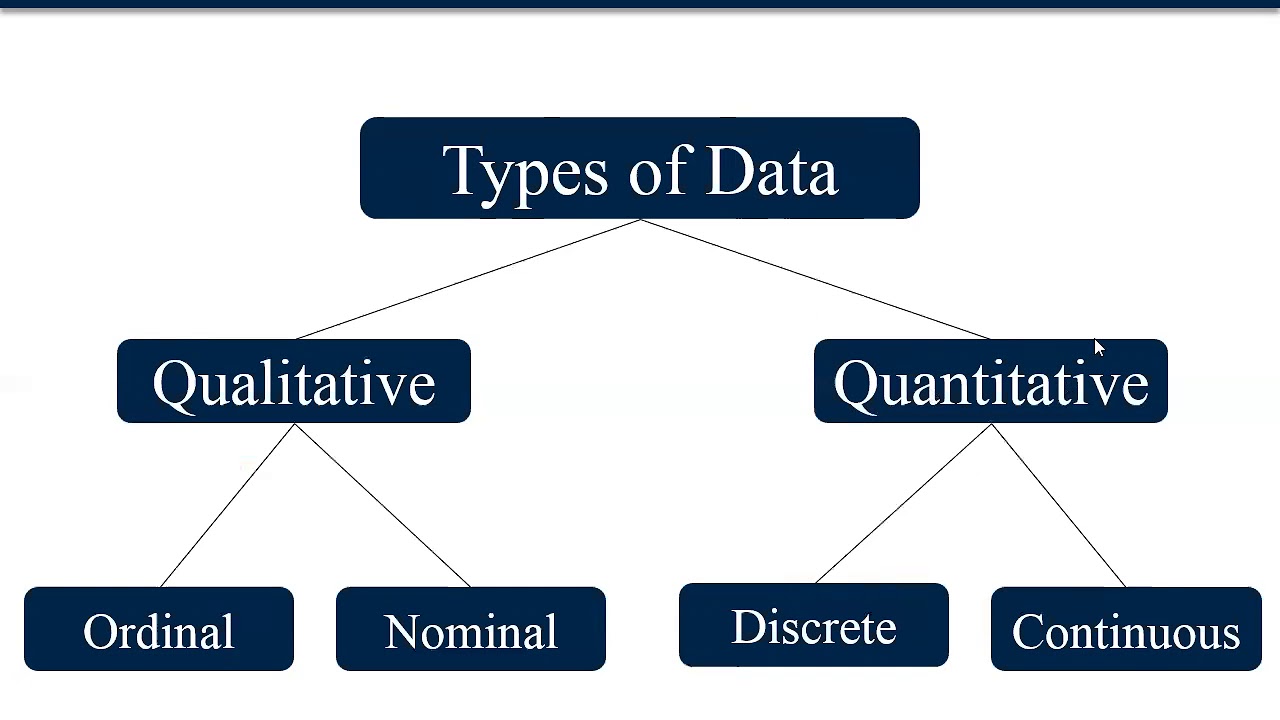
Types Of Data Youtube

15 Types Of Data, Explained (2025)
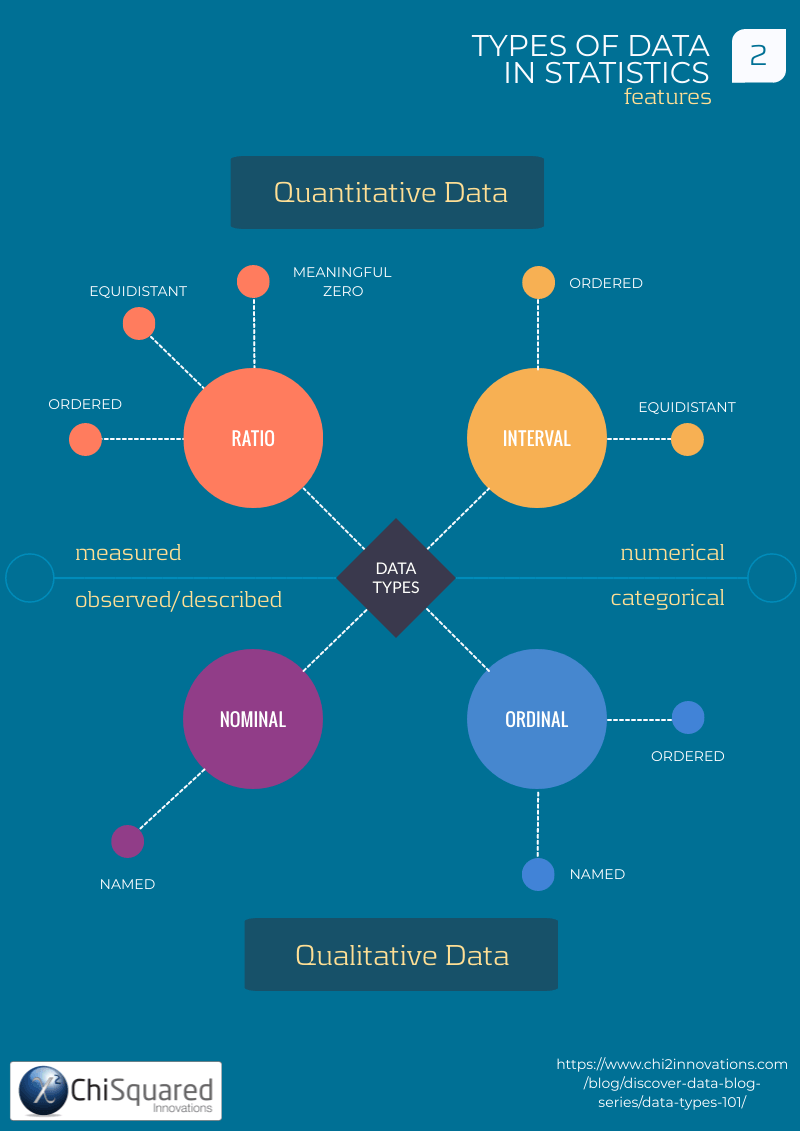
4 Types Of Data In Statistics Definitions, Uses & Examples
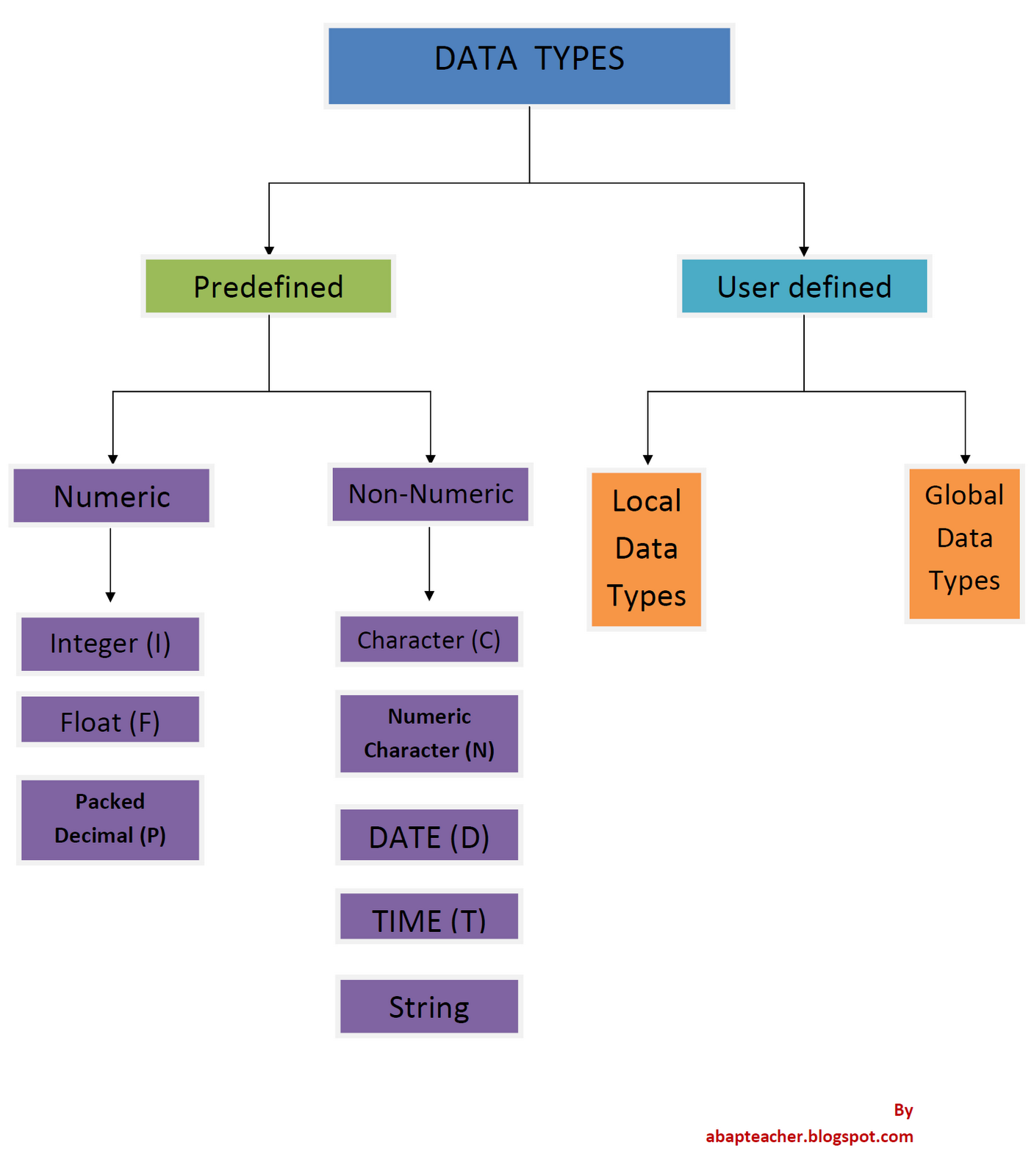
Sapabap Data Types
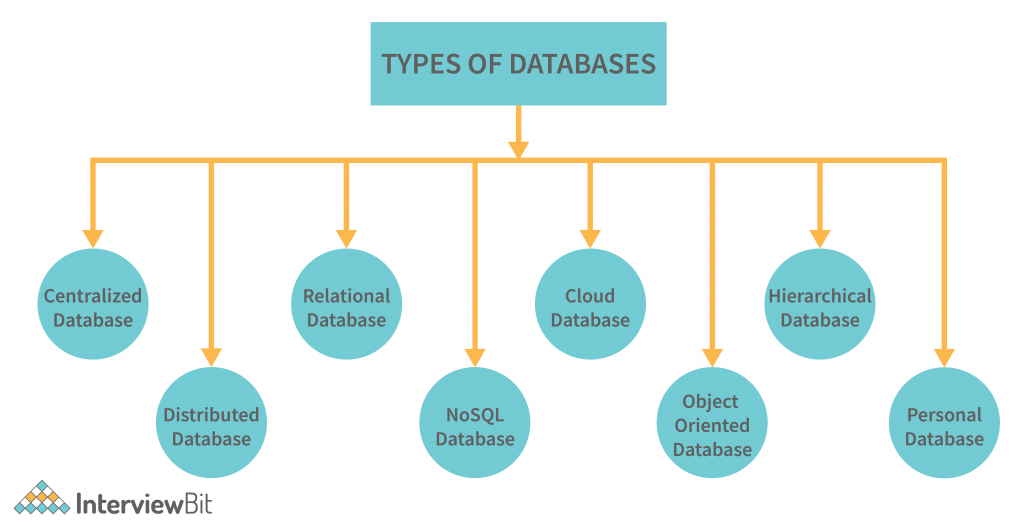
Types Of Databases Interviewbit
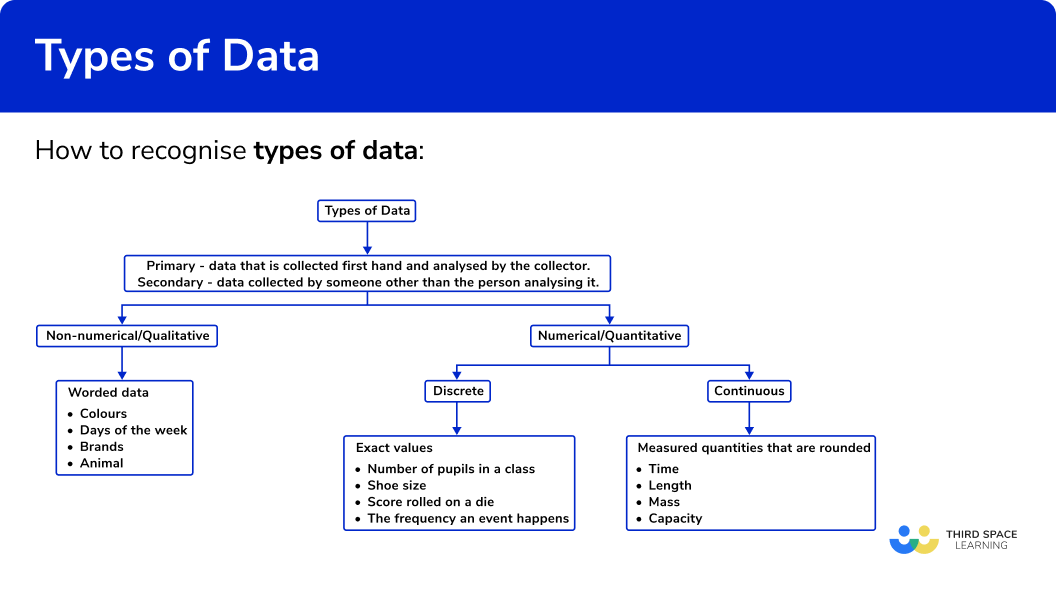
Types Of Data Gcse Maths Steps, Examples & Worksheet
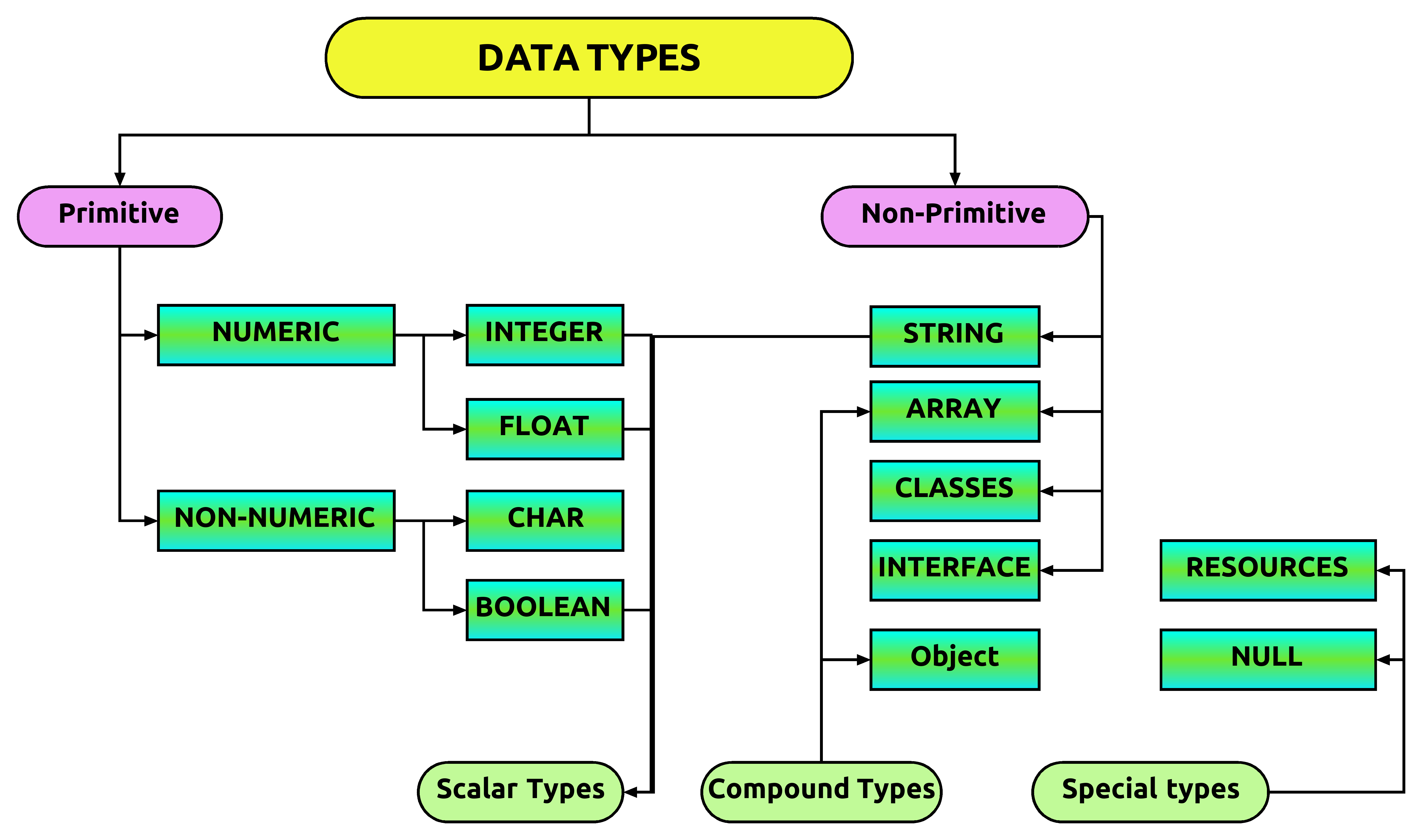
Data Types Tutorial Blog

Diagram Of Types Data Quizlet

Data Types A Maths Dictionary For Kids Quick Reference By Jenny Eather
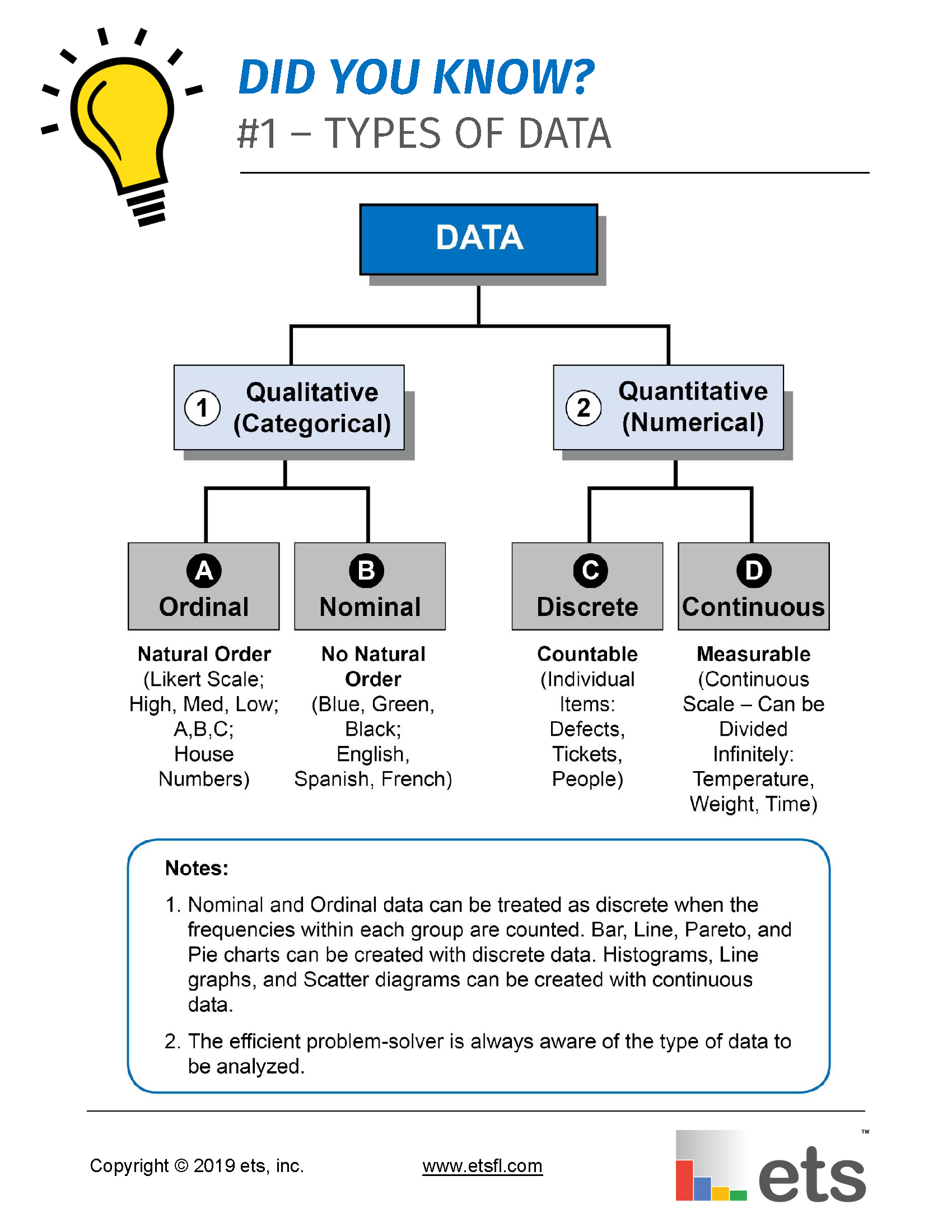
Do You Know The Types Of Data? Ets
Data Analysis Types Concepts & Examples Analytics Yogi

What Are Data Types And Why They Important? Amplitude